
الدليل الشامل إلى النماذج مفتوحة المصدر (Open Source Models): كيف تقود ثورة الذكاء الاصطناعي؟
لماذا أصبحت النماذج مفتوحة المصدر محور اهتمام المطورين والباحثين حول العالم؟

النماذج مفتوحة المصدر هي أنظمة ذكاء اصطناعي تُتاح أوزانها (Weights) وبنيتها المعمارية (Architecture) وأحياناً بيانات تدريبها للعموم، مما يسمح لأي مطور أو باحث بتشغيلها وتعديلها وتحسينها بحرية. تمثل هذه النماذج ركيزة أساسية في ديمقراطية الذكاء الاصطناعي؛ إذ تكسر احتكار الشركات الكبرى وتمنح المجتمع التقني أدوات بناء متقدمة دون قيود ترخيص تقليدية.
هل وجدت نفسك يوماً أمام مشروع يحتاج إلى نموذج ذكاء اصطناعي قوي، لكنك تراجعت بسبب التكلفة الباهظة لواجهات برمجة التطبيقات المدفوعة؟ أو ربما كنت قلقاً من إرسال بيانات عملائك الحساسة إلى خوادم شركة أجنبية لا تعرف كيف تتعامل معها؟ أنت لست وحدك في هذا. آلاف المطورين والباحثين العرب يواجهون هذا المأزق يومياً. الخبر الجيد هو أن هذا المقال سيضع بين يديك كل ما تحتاجه لفهم النماذج مفتوحة المصدر من الألف إلى الياء، من آلية عملها الداخلية إلى كيفية تشغيلها على جهازك المحلي، ومن مزاياها الإستراتيجية إلى تحدياتها الواقعية. ستخرج من هنا وأنت تعرف بالضبط أي نموذج يناسب مشروعك، وكيف تبدأ فوراً.
⚡ خلاصة المقال في دقيقة واحدة
حقائق أساسية
- النماذج مفتوحة المصدر تُتيح أوزانها وبنيتها للجميع، مما يسمح بالتشغيل المحلي والتعديل الحر دون إرسال البيانات لطرف ثالث.
- أكثر من 65% من النماذج البارزة الصادرة في 2023 كانت مفتوحة المصدر وفقاً لتقرير Stanford AI Index.
- نماذج مثل Llama 3.1 وDeepSeek-V3 حققت نتائج تنافس GPT-4 بتكلفة أقل بعشرات المرات.
تطبيقات عملية
- المؤسسات الصحية تستخدمها لبناء مساعدين طبيين ذكيين مع حماية كاملة لبيانات المرضى.
- تقنيات LoRA وQLoRA تتيح تخصيص النماذج لمهام محددة ببطاقة رسوميات واحدة فقط.
- أدوات مثل Ollama وLM Studio تجعل تشغيل النماذج محلياً في متناول المبتدئين.
تنبيهات جوهرية
- تشغيل النماذج الكبيرة يتطلب عتاداً متخصصاً (GPU بذاكرة 24 جيجابايت على الأقل للنماذج المتوسطة).
- مشكلة الهلوسة (Hallucination) موجودة في كل النماذج، ويجب بناء طبقات تحقق مستقلة.
- الأطر التنظيمية لاستخدام هذه النماذج في المنطقة العربية لا تزال في طور التبلور.
كيف بدأت ثورة النماذج مفتوحة المصدر في الذكاء الاصطناعي؟
لم يكن مشهد الذكاء الاصطناعي قبل عام 2023 يشبه ما نراه اليوم. كانت الشركات الكبرى مثل OpenAI وGoogle تحتفظ بنماذجها خلف أبواب موصدة، ولم يكن أمام المطورين المستقلين سوى دفع اشتراكات شهرية مرتفعة للوصول إلى قدرات لغوية متقدمة عبر واجهات برمجة التطبيقات (APIs). لقد كان الوضع أشبه بعالم تملك فيه شركتان أو ثلاث مفاتيح المعرفة كلها.
ثم جاء التحول. في فبراير 2023، سرّبت وثيقة داخلية منسوبة لأحد مهندسي Google تحمل عنوان “We Have No Moat” (ليس لدينا خندق دفاعي)، وأشارت بوضوح إلى أن المجتمع مفتوح المصدر يتقدم بسرعة مذهلة وأن الشركات الكبرى لن تستطيع الحفاظ على تفوقها طويلاً. كانت تلك الوثيقة بمثابة جرس إنذار هزّ الصناعة بأكملها. فقد أدركت الشركات أن نماذج الذكاء الاصطناعي مفتوحة المصدر لم تعد مجرد مشاريع هواة، بل أصبحت منافساً حقيقياً.
اليوم، في عام 2025، تجاوز عدد نماذج اللغة الكبيرة (LLMs) المتاحة على منصة Hugging Face حاجز المليون نموذج. هذا الرقم ليس مجرد إحصائية جافة؛ إنه يعكس حركة عالمية ضخمة نحو ديمقراطية الذكاء الاصطناعي. من طلاب جامعيين في الرياض إلى باحثين في مختبرات جامعة الملك عبدالله للعلوم والتقنية (KAUST)، الجميع بات قادراً على تحميل نموذج لغوي متقدم وتشغيله على خادمه الخاص.
حقيقة لافتة: وفقاً لتقرير Stanford AI Index لعام 2024، فإن 65.7% من نماذج الذكاء الاصطناعي البارزة التي صدرت في عام 2023 كانت مفتوحة المصدر، مقارنة بـ 44.4% فقط في عام 2022. هذا يعني أن الاتجاه يتسارع بشكل غير مسبوق.
ما الذي يجعل النموذج “مفتوح المصدر” فعلاً؟
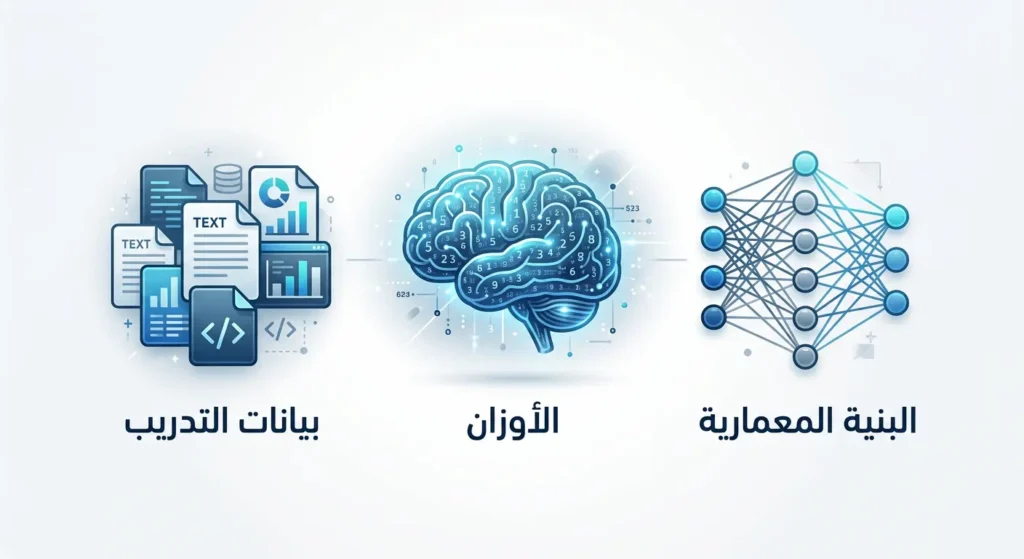
كثيرون يظنون أن مصطلح “مفتوح المصدر” يعني ببساطة أن النموذج مجاني. لكن الحقيقة أعمق من ذلك بكثير. لفهم ما يجعل نموذج الذكاء الاصطناعي مفتوحاً حقاً، علينا تشريح مكوناته الثلاثة الأساسية.
المكون الأول هو البنية المعمارية (Architecture)، وهي التصميم الهندسي للشبكة العصبية: عدد الطبقات (Layers)، ونوع آلية الانتباه (Attention Mechanism)، وطريقة ترميز المدخلات (Tokenization). عندما يكون النموذج مفتوحاً، تُنشر هذه البنية كاملة ليتمكن أي شخص من فهمها وإعادة بنائها.
المكون الثاني هو الأوزان (Weights)، وهي القلب النابض للنموذج. تخيلها كذاكرة النموذج المكتسبة بعد تدريبه على مليارات النصوص. بدون الأوزان، البنية المعمارية مجرد هيكل فارغ. حين تُصدر شركة مثل Meta أوزان نموذج Llama، فهي تمنحك فعلياً “دماغ” النموذج المدرَّب.
المكون الثالث هو بيانات التدريب (Training Data). وهنا تكمن المنطقة الرمادية. كثير من النماذج التي تُوصف بأنها مفتوحة المصدر لا تكشف عن بيانات تدريبها بالكامل. هذا ما دفع منظمة Open Source Initiative (OSI) في أكتوبر 2024 إلى إصدار تعريف رسمي جديد لمصطلح “الذكاء الاصطناعي مفتوح المصدر”، يشترط الإفصاح الكافي عن بيانات التدريب لتمكين إعادة بناء النموذج.
الفرق الجوهري بين النماذج مفتوحة ومغلقة المصدر
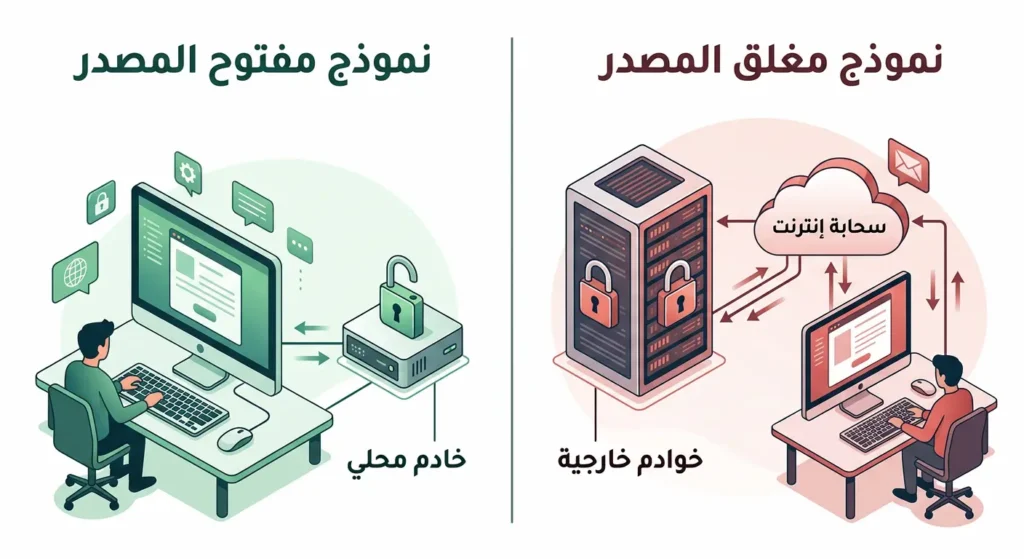
لتوضيح الفرق بين النماذج مفتوحة المصدر ومغلقة المصدر بشكل عملي، تأمل هذا السيناريو:
- النموذج المغلق (مثل GPT-4o): أنت ترسل نصك إلى خوادم OpenAI عبر الإنترنت. تحصل على الإجابة. لكنك لا تعرف ماذا يحدث في الداخل، ولا تستطيع تعديل سلوك النموذج جوهرياً، وبياناتك تمر عبر خوادم الشركة.
- النموذج المفتوح (مثل Llama 3.1): تحمّل النموذج على خادمك أو حاسوبك. تشغّله بدون إنترنت. تعدّل سلوكه ليناسب مجالك. بياناتك لا تغادر جهازك أبداً.
هذا الفرق ليس نظرياً فحسب. بالنسبة لشركة سعودية تعمل في القطاع الصحي مثلاً، إرسال بيانات المرضى إلى خادم خارجي قد يخالف نظام حماية البيانات الشخصية الصادر في المملكة عام 2023. وهنا تصبح النماذج مفتوحة المصدر ليست مجرد خيار تقني، بل ضرورة تنظيمية.
جدول 2: مقارنة شاملة بين النماذج مفتوحة المصدر والنماذج مغلقة المصدر
| وجه المقارنة | النماذج مفتوحة المصدر (Open Source) | النماذج مغلقة المصدر (Closed Source) |
|---|---|---|
| الوصول إلى الأوزان (Weights) | متاح للتحميل والتعديل | غير متاح، الوصول عبر API فقط |
| التخصيص والضبط الدقيق (Fine-Tuning) | ممكن بالكامل باستخدام تقنيات مثل LoRA وQLoRA | محدود جداً أو غير متاح |
| خصوصية البيانات | تحكم كامل، البيانات لا تغادر الخادم المحلي | البيانات تُرسل إلى خوادم الشركة المزودة |
| التكلفة التشغيلية | تكلفة أولية للعتاد، لكن تكلفة الاستعلام شبه معدومة | اشتراك شهري أو رسوم لكل استعلام (Pay-per-token) |
| الشفافية وقابلية التفسير | يمكن فحص البنية والأوزان وتحليل التحيزات | صندوق أسود، لا يمكن فحص العمل الداخلي |
| الدعم الفني | يعتمد على المجتمع (Community Support) | دعم فني رسمي واتفاقيات مستوى خدمة (SLA) |
| سهولة البدء | يتطلب خبرة تقنية في التثبيت والتشغيل | سهل جداً، استدعاء API ببضعة أسطر |
| متطلبات العتاد | يحتاج GPU قوية محلياً أو سحابياً | لا يحتاج عتاداً خاصاً، يعمل عبر الإنترنت |
| التحديثات | يدوية، تعتمد على المستخدم | تلقائية من الشركة المزودة |
| أمثلة بارزة | Llama 3.1, Mistral, Falcon, Gemma, Jais | GPT-4o, Claude 3.5, Gemini Ultra |
| المصادر: Stanford HAI AI Index Report 2024 | Open Source Initiative – OSAID v1.0 | ||
اقرأ أيضاً: كيفية حماية البيانات الشخصية على الإنترنت: كيف تحمي خصوصيتك الرقمية؟
كيف يساهم مجتمع المطورين في تحسين هذه النماذج؟
من أجمل ما يميز الذكاء الاصطناعي مفتوح المصدر هو ظاهرة التحسين الجماعي (Community-Driven Improvement). فبمجرد إصدار نموذج ما، يبدأ آلاف المطورين حول العالم بالعمل عليه: البعض يُجري عمليات ضبط دقيق (Fine-Tuning) لتخصصات معينة، وآخرون يُنشئون نسخاً مضغوطة (Quantized) يمكن تشغيلها على أجهزة أقل قوة، وفريق ثالث يكتب توثيقاً (Documentation) يُسهّل على المبتدئين البدء.
منصة Hugging Face تُعَدُّ المركز العصبي لهذا المجتمع. فقد أصبحت بمثابة “GitHub للذكاء الاصطناعي”، حيث يمكن لأي شخص رفع نموذجه المعدَّل ومشاركته مع العالم. كما أن أدوات مثل Ollama وLM Studio جعلت تشغيل النماذج مفتوحة المصدر محلياً أمراً بسيطاً لا يتطلب أكثر من بضع نقرات.
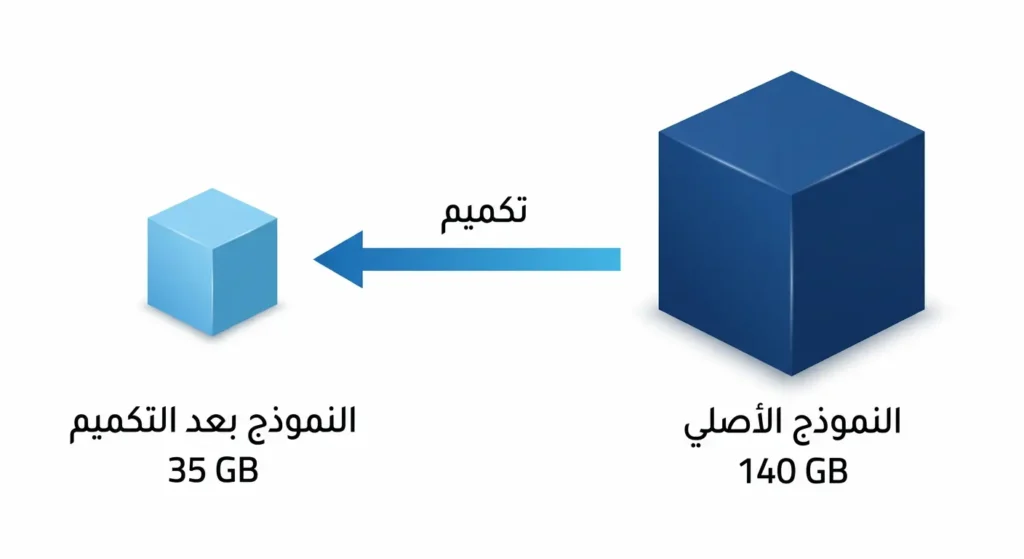
معلومة تقنية مهمة: عملية “التكميم” أو الضغط (Quantization) هي تقنية تُقلّص حجم النموذج بنسبة تصل إلى 75% مع فقدان طفيف في الدقة. بفضلها، أصبح بالإمكان تشغيل نموذج بحجم 70 مليار معامل (Parameter) على بطاقة رسوميات (GPU) واحدة بدلاً من عنقود خوادم كامل.
من هم عمالقة النماذج مفتوحة المصدر في 2025؟
الساحة تتغير بسرعة مذهلة. كل شهر تقريباً يظهر نموذج جديد يُزيح سابقه عن القمة. لكن هناك عائلات من النماذج أثبتت نفسها كأعمدة أساسية في هذا المجال. دعني آخذك في جولة سريعة بين أبرزها.
عائلة Llama من Meta
بدأت القصة مع Llama 1 في فبراير 2023، ثم Llama 2 في يوليو من العام نفسه. لكن النقلة الحقيقية جاءت مع Llama 3 وLlama 3.1 في عام 2024. النسخة الأكبر (Llama 3.1 405B) تحتوي على 405 مليارات معامل، وحققت نتائج منافسة لـ GPT-4 في عدة معايير قياسية (Benchmarks). في مطلع 2025، أصدرت Meta نموذج Llama 4 بعدة أحجام، بما فيها نسخة “Scout” ونسخة “Maverick”، مع دعم أصلي لمعالجة الصور والنصوص معاً (Multimodal).
ما يميز عائلة Llama هو سياسة الترخيص المرنة نسبياً. فقد سمحت Meta باستخدامها تجارياً للشركات التي يقل عدد مستخدميها النشطين شهرياً عن 700 مليون مستخدم، وهو ما يشمل عملياً كل الشركات تقريباً باستثناء عمالقة التكنولوجيا أنفسهم.
نماذج Mistral: الحصان الأسود الأوروبي
شركة Mistral AI الفرنسية فاجأت الجميع. تأسست في أبريل 2023، وخلال أشهر قليلة أصدرت نموذج Mistral 7B الذي تفوق على نماذج أكبر منه حجماً بمرتين أو ثلاث. ثم جاء Mixtral 8x7B بتقنية “مزيج الخبراء” (Mixture of Experts – MoE) التي تُنشّط جزءاً فقط من معاملات النموذج عند كل استعلام، مما يوفر في تكلفة الحوسبة بشكل كبير.
في عام 2025، أصدرت Mistral نماذج جديدة من عائلة Mistral Large وMistral Medium، مع تركيز خاص على اللغات الأوروبية والعربية. هذا التوجه جعل Mistral الخيار المفضل للعديد من الشركات الناشئة في منطقة الخليج؛ إذ إنها تقدم أداءً ممتازاً بتكلفة حوسبة أقل بكثير من النماذج الأضخم.
نماذج Gemma من Google وFalcon من معهد الابتكار التكنولوجي (TII)
أطلقت Google عائلة Gemma في فبراير 2024 كنسخ مفتوحة مستوحاة من تقنيات نموذجها المغلق Gemini. تأتي Gemma بأحجام صغيرة نسبياً (2B و7B معامل)، مما يجعلها مثالية للتطبيقات التي تعمل على أجهزة محدودة الموارد (Edge Devices). في 2025 صدرت Gemma 3 بقدرات متعددة الوسائط محسنة.
أما نموذج Falcon، فيحمل أهمية خاصة للقارئ العربي. طوّره معهد الابتكار التكنولوجي (TII) في أبو ظبي، وعند إطلاقه في مايو 2023 تصدّر قائمة Hugging Face لأفضل النماذج المفتوحة. نموذج Falcon 180B كان من أكبر النماذج مفتوحة المصدر حينها. ورغم أن المنافسة اشتدت لاحقاً، يبقى Falcon دليلاً حياً على أن المنطقة العربية قادرة على المنافسة في هذا المضمار.
جدول 1: مقارنة أبرز النماذج مفتوحة المصدر الرائدة حتى عام 2025
| النموذج | الجهة المطورة | عدد المعاملات (Parameters) | الترخيص التجاري | دعم اللغة العربية | أبرز الميزات |
|---|---|---|---|---|---|
| Llama 3.1 | Meta | 8B / 70B / 405B | نعم (بشروط) | محدود | أداء ينافس GPT-4، سياق طويل يصل إلى 128K رمز |
| Mistral Large | Mistral AI | حتى 123B | نعم | جيد | تقنية مزيج الخبراء (MoE)، كفاءة حوسبية عالية |
| Gemma 3 | 2B / 7B / 27B | نعم | محدود | حجم صغير مثالي لأجهزة الحافة (Edge Devices) | |
| Falcon 180B | TII (أبو ظبي) | 7B / 40B / 180B | نعم | جيد | نموذج عربي المنشأ، دُرِّب على بيانات RefinedWeb |
| Qwen 2.5 | Alibaba | 7B / 14B / 72B | نعم | جيد جداً | دعم قوي للغات الآسيوية والعربية |
| DeepSeek-V3 | DeepSeek | 671B (MoE) | نعم | متوسط | تكلفة تدريب منخفضة جداً (~$5.5M)، أداء ينافس الأقوى |
| Jais | TII + MBZUAI | 13B / 30B | نعم | ممتاز | أكبر نموذج عربي مفتوح، يدعم لهجات متعددة |
| المصادر: Stanford HAI AI Index Report 2024 | Hugging Face Open LLM Leaderboard | الأوراق البحثية الرسمية لكل نموذج | |||||
هل تعلم؟ نموذج Falcon 40B دُرِّب على مجموعة بيانات RefinedWeb التي تحتوي على ما يقارب 5 تريليونات رمز (Token) مستخلصة من الويب بعد تنقية وتصفية دقيقة. هذا يجعلها واحدة من أكبر مجموعات بيانات التدريب المفتوحة على الإطلاق.
اقرأ أيضاً: تطبيقات الذكاء الاصطناعي في التعليم: الفرص والتحديات
نماذج أخرى تستحق المتابعة
لا يمكن إغفال نماذج Qwen من شركة Alibaba الصينية، التي حققت نتائج لافتة في عام 2025 مع إصدار Qwen 2.5. وكذلك نموذج DeepSeek-V3 من شركة DeepSeek الصينية، الذي أحدث ضجة واسعة في يناير 2025 بتحقيقه أداءً ينافس أقوى النماذج المغلقة بتكلفة تدريب تُقدَّر بأقل من 6 ملايين دولار فقط — وهو رقم زهيد مقارنة بمئات الملايين التي تنفقها الشركات الأمريكية الكبرى.
لماذا تختار الشركات النماذج مفتوحة المصدر؟ المزايا الإستراتيجية والتنافسية
مثال تطبيقي: مستشفى سعودي يبني مساعداً طبياً ذكياً

لنتخيل سيناريو واقعياً. مستشفى كبير في الرياض يريد بناء مساعد ذكي يساعد الأطباء في تلخيص السجلات الطبية وتقديم اقتراحات تشخيصية أولية. أمام فريق تقنية المعلومات خياران:
الخيار الأول: استخدام واجهة GPT-4o من OpenAI. سريع البدء، لكن كل استعلام يُكلف مالاً، والبيانات الطبية الحساسة تُرسل إلى خوادم خارج المملكة. هذا قد يتعارض مع متطلبات هيئة الحكومة الرقمية السعودية بشأن توطين البيانات.
الخيار الثاني: تحميل نموذج Llama 3.1 70B على خوادم المستشفى المحلية، ثم إجراء ضبط دقيق (Fine-Tuning) باستخدام بيانات طبية سعودية مُجهَّلة الهوية (De-identified). النتيجة: نموذج متخصص في المصطلحات الطبية العربية، يعمل بدون إنترنت، والبيانات لا تغادر جدران المستشفى.
هذا ليس سيناريو خيالياً. مشاريع مشابهة تُنفَّذ حالياً في مستشفيات ومراكز أبحاث عبر المنطقة. وهي توضح لماذا أصبحت نماذج الذكاء الاصطناعي مفتوحة المصدر خياراً إستراتيجياً وليس مجرد بديل اقتصادي.
اقرأ أيضاً:
- تطبيقات الذكاء الاصطناعي في علم الأدوية: التحديات والفرص
- علاج السرطان: التقنيات الحديثة والابتكارات المستقبلية
الخصوصية وأمان البيانات
في عصر تتزايد فيه التشريعات المتعلقة بحماية البيانات — من نظام حماية البيانات الشخصية السعودي (PDPL) إلى اللائحة الأوروبية العامة لحماية البيانات (GDPR) — يُعَدُّ التشغيل المحلي (Local Hosting) ميزة لا تُقدَّر بثمن. حين تُشغّل النموذج على خوادمك الخاصة، أنت تتحكم كلياً في مسار البيانات. لا وسيط، ولا طرف ثالث، ولا مخاوف من اختراقات تطال بيانات عملائك أثناء انتقالها عبر الشبكة.
هذا الأمر يكتسب أهمية مضاعفة في القطاعات الحساسة: البنوك، شركات التأمين، الجهات الحكومية، والمؤسسات العسكرية. فقد أشار تقرير صادر عن شركة IBM لعام 2024 إلى أن متوسط تكلفة اختراق البيانات عالمياً بلغ 4.88 مليون دولار. بالمقابل، تشغيل نموذج مفتوح المصدر محلياً يُقلّص سطح الهجوم (Attack Surface) بشكل جذري.
اقرأ أيضاً: الأمن السيبراني: المبادئ الأساسية وأهميته في العصر الرقمي
التخصيص الدقيق: تكييف النموذج لمهامك المحددة
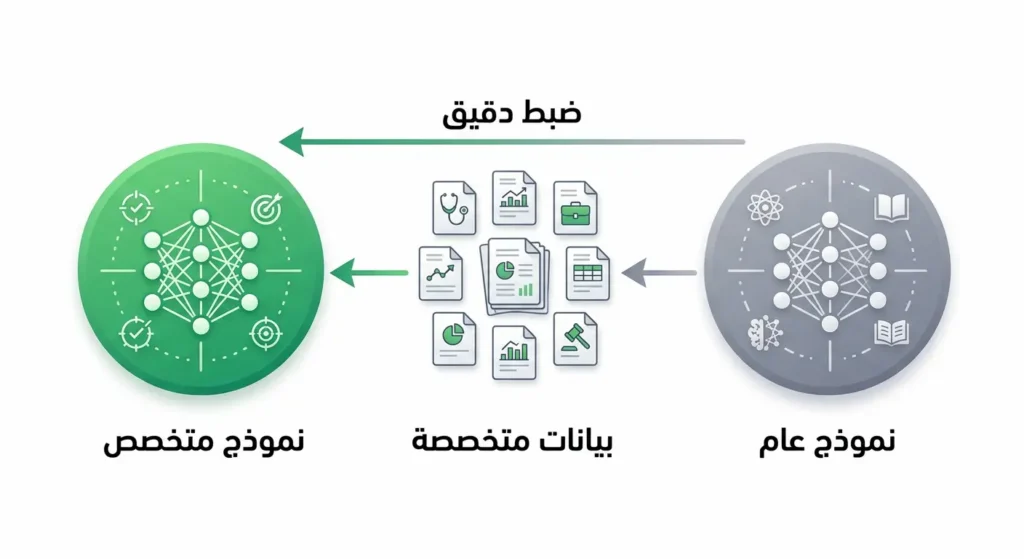
من أقوى مزايا النماذج مفتوحة المصدر هي إمكانية الضبط الدقيق (Fine-Tuning). بدلاً من استخدام نموذج عام يعرف كل شيء بشكل سطحي، يمكنك تدريبه على بياناتك الخاصة ليصبح خبيراً في مجالك. تقنيات مثل LoRA (Low-Rank Adaptation) وQLoRA جعلت هذه العملية ممكنة حتى على بطاقة رسوميات واحدة بذاكرة 24 جيجابايت.
فقد أثبتت دراسة منشورة في مجلة Nature Medicine عام 2024 أن نموذجاً مفتوح المصدر (مبنياً على Llama 2) بعد ضبطه الدقيق على بيانات طبية متخصصة تفوّق على GPT-4 في مهام التشخيص السريري لأمراض معينة. هذا يُظهر أن الحجم ليس كل شيء؛ التخصيص يمكن أن يتغلب على القوة الحوسبية الخام.
الشفافية العلمية وتقليل الانحياز
حين يكون النموذج مغلقاً، لا يمكنك معرفة لماذا اتخذ قراراً معيناً. هل يحمل تحيزات عرقية أو جندرية أو ثقافية؟ لا سبيل لمعرفة ذلك إلا بالاختبار الخارجي. على النقيض من ذلك، النماذج مفتوحة المصدر تتيح للباحثين فحص الأوزان وتحليل سلوك النموذج من الداخل. وهذا ما يُعرف بـ “قابلية التفسير” (Interpretability).
أثبتت دراسة منشورة في وقائع مؤتمر NeurIPS عام 2023 أن النماذج المفتوحة تُسهّل بشكل ملموس اكتشاف التحيزات المخفية وتصحيحها، مقارنة بالنماذج المغلقة التي لا تسمح بأي وصول داخلي.
اقرأ أيضاً: الانحياز المعرفي: الأسباب، الأنواع، والتأثير على القرار
التكلفة الاقتصادية: حسابات واقعية
دعنا نتحدث بالأرقام. استخدام واجهة GPT-4o يُكلف تقريباً 5 دولارات لكل مليون رمز إدخال (Input Token) و15 دولاراً لكل مليون رمز إخراج (Output Token) وفقاً لتسعيرة OpenAI في مطلع 2025. لشركة تُجري ملايين الاستعلامات يومياً، الفاتورة الشهرية قد تصل إلى عشرات الآلاف من الدولارات.
بالمقابل، تشغيل نموذج مفتوح المصدر مثل Llama 3.1 70B على خادم سحابي مع بطاقة NVIDIA A100 يكلف ما بين 1 إلى 3 دولارات في الساعة حسب مزود الخدمة السحابية. بعد حساب الاستهلاك، التكلفة لكل مليون رمز قد تنخفض إلى أقل من دولار واحد. هذا الفارق الاقتصادي الهائل يُفسّر لماذا تتسابق الشركات الناشئة على تبني الذكاء الاصطناعي مفتوح المصدر.
رقم صادم: أعلنت شركة DeepSeek في يناير 2025 أن تكلفة تدريب نموذجها DeepSeek-V3 (الذي ينافس GPT-4) بلغت حوالي 5.576 مليون دولار فقط. هذا الرقم أقل بـ 20 مرة تقريباً من التكلفة المُقدَّرة لتدريب GPT-4، والتي تتجاوز 100 مليون دولار وفقاً لتقديرات مختلفة.
ما التحديات التي تواجه النماذج مفتوحة المصدر اليوم؟
متطلبات العتاد: الفيل في الغرفة

لنكن صريحين. تشغيل نماذج اللغة الكبيرة ليس كتشغيل تطبيق عادي على حاسوبك. نموذج بحجم 70 مليار معامل يحتاج في شكله الأصلي (بدقة FP16) إلى ما يقارب 140 جيجابايت من ذاكرة GPU. هذا يعني أنك تحتاج إلى بطاقتَي NVIDIA A100 بسعة 80 جيجابايت لكل منهما على الأقل.
بالطبع، تقنيات التكميم (Quantization) خفّفت هذا العبء بشكل كبير. نسخة 4-bit من نموذج 70B يمكن أن تعمل على بطاقة واحدة بسعة 48 جيجابايت. لكن حتى هذا يتطلب استثماراً مالياً في عتاد متخصص قد لا يكون متاحاً لكل مطور فردي أو شركة ناشئة صغيرة.
في السعودية ودول الخليج، تتوفر حلول سحابية محلية مثل خدمات شركة stc cloud وشركة Alibaba Cloud في المنطقة، لكن الوعي بكيفية تشغيل النماذج مفتوحة المصدر محلياً لا يزال في مراحله الأولى. وهنا تبرز الحاجة إلى مبادرات تعليمية وتدريبية عربية متخصصة.
اقرأ أيضاً: الحوسبة السحابية (Cloud Computing): المفهوم، النماذج، والتطبيقات
مشكلة الهلوسة: حين يختلق النموذج معلومات

كل نماذج اللغة الكبيرة — سواء مفتوحة أو مغلقة المصدر — تعاني من ظاهرة “الهلوسة” (Hallucination)، أي توليد معلومات تبدو مقنعة لكنها خاطئة تماماً. الفرق هو أن الشركات التي تقف خلف النماذج المغلقة تستثمر مبالغ ضخمة في أنظمة الحماية (Guardrails) والتعلم من التغذية الراجعة البشرية (RLHF) لتقليل هذه المشكلة.
مع النماذج مفتوحة المصدر، مسؤولية بناء هذه الحواجز تقع على عاتقك أنت. هذا يعني أنك بحاجة إلى بناء طبقات تحقق (Validation Layers) وأنظمة استرجاع معزَّز بالتوليد (RAG – Retrieval Augmented Generation) لربط مخرجات النموذج بمصادر بيانات موثوقة.
غياب الدعم الفني وتحدي الصيانة
حين تستخدم واجهة مدفوعة من OpenAI أو Google، لديك فريق دعم فني، واتفاقيات مستوى خدمة (SLA)، وتحديثات تلقائية. مع النماذج مفتوحة المصدر، أنت المسؤول عن كل شيء: التثبيت، التحديث، مراقبة الأداء، وحل المشكلات. هذا يتطلب فريقاً تقنياً ذا كفاءة عالية في هندسة تعلم الآلة (MLOps).
تنبيه مهم: غياب الدعم الفني الرسمي لا يعني غياب المساعدة تماماً. مجتمعات مثل Reddit (/r/LocalLLaMA) وDiscord الخاصة بـ Hugging Face ومنتديات GitHub تضم عشرات الآلاف من المطورين النشطين الذين يتبادلون الحلول يومياً. المفتاح هو أن تكون مستعداً للبحث والتجربة بنفسك.
مخاطر الاستخدام السيئ
هذا الجانب لا يمكن تجاهله. حين تكون أوزان النموذج متاحة للجميع، فإن الاستخدامات الضارة تصبح ممكنة أيضاً. توليد الأخبار المزيفة (Deepfake Text)، كتابة برمجيات خبيثة (Malware)، وشنّ هجمات تصيّد احتيالي (Phishing) متقدمة — كلها سيناريوهات واقعية.
في الولايات المتحدة، أصدر الرئيس الأمريكي أمراً تنفيذياً في أكتوبر 2023 يفرض على مطوري النماذج الكبيرة إجراء تقييمات أمنية قبل الإطلاق. وفي الاتحاد الأوروبي، يُصنّف قانون الذكاء الاصطناعي (EU AI Act) الصادر في 2024 النماذج مفتوحة المصدر ضمن فئة خاصة مع بعض الاستثناءات.
أما في المملكة العربية السعودية، فإن الهيئة السعودية للبيانات والذكاء الاصطناعي (SDAIA) تعمل على وضع أطر تنظيمية لاستخدام الذكاء الاصطناعي تتوافق مع رؤية 2030. الجدير بالذكر أن المملكة تستثمر بكثافة في البنية التحتية للذكاء الاصطناعي، مع مشاريع مثل صندوق الاستثمارات العامة الذي ضخ مليارات في شركات التكنولوجيا. لكن الإطار التنظيمي لاستخدام النماذج المفتوحة لا يزال في طور التبلور.
إحصائية حديثة: وفقاً لتقرير Europol عام 2024 حول التهديدات الرقمية، زادت محاولات الاحتيال الإلكتروني المُعزَّزة بالذكاء الاصطناعي بنسبة 135% خلال عام واحد. جزء من هذه الزيادة يُعزى إلى سهولة الوصول إلى نماذج لغوية مفتوحة قوية.
اقرأ أيضاً:
- الجدار الناري وأجهزة الحماية من الفيروسات: أساسيات الأمن السيبراني
- الديدان الإلكترونية: التعريف، الانتشار، واستراتيجيات الحماية
كيف تُوظَّف النماذج مفتوحة المصدر في العلوم والأبحاث؟
تحليل الجينوم وتطوير الأدوية
يشهد مجال المعلوماتية الحيوية (Bioinformatics) ثورة هادئة بفضل نماذج الذكاء الاصطناعي مفتوحة المصدر. نماذج مثل ESMFold من Meta (المبني على بنية مفتوحة) يمكنها التنبؤ بالبنية الثلاثية الأبعاد للبروتينات بدقة مذهلة وبسرعة تفوق الطرق التقليدية بآلاف المرات.
في مجال اكتشاف الأدوية، تُستخدم نماذج لغوية متخصصة لتحليل ملايين الأوراق البحثية واستخلاص التفاعلات الدوائية المحتملة. أثبتت دراسة منشورة في مجلة Nature Biotechnology عام 2023 أن نظاماً مبنياً على نماذج مفتوحة المصدر تمكن من تحديد مرشحين دوائيين جدد لعلاج التليف الكبدي في أسابيع بدلاً من سنوات.
هذا النوع من التطبيقات يكتسب أهمية خاصة في المنطقة العربية. مركز الملك عبدالله العالمي للأبحاث الطبية (KAIMRC) في الرياض يعمل على مشاريع تستخدم نماذج مفتوحة لتحليل بيانات جينومية خاصة بالسكان المحليين، بهدف تطوير علاجات مخصصة تناسب التركيبة الجينية للمنطقة.
اقرأ أيضاً:
- الحمض النووي (DNA): التركيب، الوظيفة، والأهمية
- علم الأدوية (Pharmacology): دراسة تفاعل الأدوية مع الكائن الحي
البرمجة وتطوير البرمجيات
نماذج توليد الشيفرة البرمجية (Code Generation) من أكثر تطبيقات نماذج اللغة الكبيرة نجاحاً. نموذج Code Llama من Meta، وStarCoder 2 من مبادرة BigCode، وDeepSeek-Coder — كلها نماذج مفتوحة متخصصة في كتابة الشيفرات البرمجية ومراجعتها وشرحها.
فما الذي يميزها عن أداة مثل GitHub Copilot؟ الإجابة بسيطة: التحكم الكامل. يمكنك ضبط النموذج على قاعدة الشيفرة الخاصة بشركتك ليفهم أنماط البرمجة المستخدمة داخلياً. كما يمكنك التأكد من أن الشيفرة المُولَّدة لا تنتهك حقوق ملكية فكرية — وهو هاجس حقيقي مع الأدوات المغلقة التي دُرِّبت على مستودعات عامة دون إذن صريح من أصحابها.
تحليل البيانات العلمية ومعالجة اللغات الطبيعية
في العلوم الاجتماعية والإنسانية، تُستخدم النماذج مفتوحة المصدر لتحليل كميات هائلة من النصوص: تغريدات، مقالات صحفية، وثائق تاريخية. مشاريع مثل AraGPT2 وJais (النموذج العربي الذي طوّره معهد الابتكار التكنولوجي بالتعاون مع جامعة محمد بن زايد للذكاء الاصطناعي) تُمثّل خطوات مهمة نحو بناء نماذج تفهم اللغة العربية بكل تعقيداتها ولهجاتها.
نموذج Jais تحديداً يُعَدُّ إنجازاً عربياً بارزاً. صدر في أغسطس 2023 بحجم 13 مليار معامل، وهو أكبر نموذج لغوي عربي مفتوح المصدر في حينه. دُرِّب على مزيج من النصوص العربية والإنجليزية، ويدعم الفصحى واللهجات الخليجية والمصرية والشامية. في 2024 و2025 صدرت إصدارات محدثة مع تحسينات في الأداء ودعم المحادثات.
معلومة ملهمة: مشروع BLOOM، الذي أطلقته مبادرة BigScience في 2022، كان أول نموذج لغوي ضخم (176 مليار معامل) يُدرَّب بشكل تعاوني بين أكثر من 1,000 باحث من 70 دولة. غطّى 46 لغة بشرية و13 لغة برمجة. كان ذلك دليلاً عملياً على أن التعاون المفتوح يمكن أن ينتج نماذج تنافس إنتاج الشركات العملاقة.
اقرأ أيضاً: البيانات الضخمة: كيف يحول الإحصاء ملايين الملاحظات إلى معرفة قابلة للتطبيق؟
كيف تُشغّل النماذج مفتوحة المصدر على جهازك المحلي؟
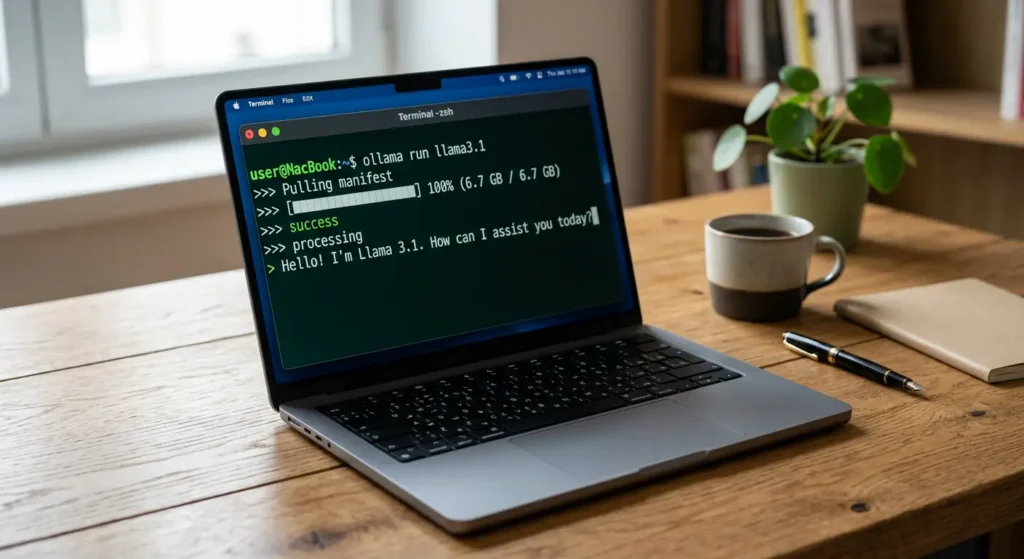
هذا السؤال هو ما يبحث عنه كثير من المطورين المبتدئين. كيفية تشغيل النماذج مفتوحة المصدر محلياً أصبح أسهل مما تتخيل بفضل أدوات حديثة. إليك أبرز الطرق:
أداة Ollama: أبسط طريقة على الإطلاق. تثبّتها على جهازك (Windows أو Mac أو Linux)، ثم تكتب أمراً واحداً في سطر الأوامر مثل:
ollama run llama3.1وخلال دقائق يكون النموذج جاهزاً للعمل. تدعم Ollama عشرات النماذج وتتولى عمليات التكميم تلقائياً.
أداة LM Studio: توفر واجهة رسومية سهلة الاستخدام. تتصفح النماذج المتاحة، تحمّل ما يناسبك، وتبدأ المحادثة فوراً. مثالية لمن لا يحب التعامل مع سطر الأوامر.
مكتبة vLLM: للمطورين الذين يريدون تشغيل النموذج كخادم API محلي لخدمة تطبيقاتهم. تتميز بكفاءة عالية في التعامل مع الطلبات المتزامنة (Concurrent Requests).
منصة Hugging Face Transformers: المكتبة الأشهر في عالم تعلم الآلة. تتيح تحميل أي نموذج مفتوح وتشغيله ببضعة أسطر من شيفرة Python. مناسبة للباحثين الذين يريدون تحكماً كاملاً.
الحد الأدنى للعتاد يعتمد على حجم النموذج. نموذج بحجم 7 مليارات معامل (بتكميم 4-bit) يمكن أن يعمل على بطاقة رسوميات بذاكرة 8 جيجابايت. أما نموذج 13B فيحتاج 16 جيجابايت. النماذج الأكبر (70B وما فوق) تتطلب عتاداً أكثر تخصصاً.
نصيحة عملية: إذا كنت مبتدئاً وتريد تجربة النماذج مفتوحة المصدر فوراً دون أي استثمار في العتاد، ابدأ بمنصة Google Colab المجانية التي توفر وصولاً محدوداً إلى وحدات GPU. يمكنك تشغيل نماذج بحجم 7B بسهولة. لاحقاً، حين تتأكد من احتياجاتك، انتقل إلى حل محلي أو سحابي مناسب.
اقرأ أيضاً:
- نظام التشغيل Linux: التاريخ، المزايا، والتطبيقات
- ذاكرة الوصول العشوائي (RAM): الآلية، الأنواع، والتطور
كيف تختار النموذج المناسب لمشروعك؟
اختيار النموذج ليس قراراً عشوائياً. إنه يعتمد على عدة عوامل متشابكة:
- طبيعة المهمة: هل تحتاج إلى محادثة عامة (Chatbot)، أم تلخيص نصوص، أم توليد شيفرة برمجية، أم تحليل صور؟ كل مهمة لها نماذج تتفوق فيها.
- حجم البيانات المتوفرة للضبط الدقيق: إذا كان لديك بيانات تدريب كافية، يمكنك أخذ نموذج أساسي (Base Model) وتخصيصه. وإلا، ابحث عن نموذج مُعدَّل مسبقاً (Instruct/Chat Model).
- الموارد الحوسبية المتاحة: ميزانيتك للعتاد أو الحوسبة السحابية تحدد حجم النموذج الذي يمكنك تشغيله.
- متطلبات الخصوصية والامتثال: إذا كنت تتعامل مع بيانات حساسة، التشغيل المحلي ضروري.
- اللغة المستهدفة: إذا كان تطبيقك يخدم جمهوراً عربياً، اختر نماذج دُرِّبت على بيانات عربية كافية (مثل Jais أو Qwen 2.5 الذي يدعم العربية).
في السياق السعودي، يزداد الاهتمام ببناء نماذج محلية. مبادرات مثل مسرعة “MCIT AI Garage” وبرامج الابتعاث في تخصصات الذكاء الاصطناعي تُعدّ جيلاً جديداً من الكفاءات القادرة على التعامل مع هذه النماذج. كما أن مؤتمر LEAP التقني في الرياض أصبح منصة عالمية تُعرض فيها أحدث تطبيقات النماذج مفتوحة المصدر.
اقرأ أيضاً: الاقتصاد السعودي: كيف تحول من الاعتماد على النفط إلى التنويع الشامل؟
هل ستقضي النماذج مفتوحة المصدر على هيمنة الشركات الكبرى؟
هذا السؤال يُطرح كثيراً، والإجابة ليست بسيطة. الواقع يشير إلى أن العلاقة بين النماذج المفتوحة والمغلقة ليست لعبة صفرية (Zero-Sum Game). ما يحدث فعلياً هو تأثير تكاملي:
النماذج مفتوحة المصدر تدفع الشركات الكبرى إلى تخفيض أسعارها وتحسين منتجاتها. وفي المقابل، الابتكارات التي تطرحها الشركات الكبرى (مثل تقنيات الاستدلال المتقدمة في GPT-o1) تُلهم المجتمع المفتوح لتطوير بدائل مماثلة.
المؤشرات الحالية تقول إن الفجوة بين أفضل النماذج المغلقة وأفضل النماذج المفتوحة تتقلص بسرعة. في معيار MMLU (Massive Multitask Language Understanding)، سجل Llama 3.1 405B نتائج تقترب من GPT-4. وDeepSeek-V3 حقق نتائج منافسة لـ Claude 3.5 Sonnet في عدة معايير.
لكن هناك مجالات لا تزال النماذج المغلقة تتفوق فيها: الاستدلال المعقد متعدد الخطوات (Multi-Step Reasoning)، ومعالجة السياقات الطويلة جداً (Long Context)، والتكامل مع أدوات خارجية (Tool Use). هذه الفجوات ستتقلص مع الوقت، لكنها لن تختفي بالكامل في المدى القريب.
رأي شخصي: أعتقد أن المستقبل لن يكون “مفتوحاً بالكامل” ولا “مغلقاً بالكامل”. ما سنراه هو نظام بيئي هجين: شركات تستخدم النماذج المفتوحة كقاعدة، ثم تبني فوقها طبقات خاصة (Proprietary Layers) تُضيف قيمة مميزة. وهذا بالضبط ما بدأنا نراه مع شركات مثل Together AI وAnyscale وFireworks AI.
أسئلة شائعة حول النماذج مفتوحة المصدر
هل يمكن استخدام النماذج مفتوحة المصدر في المشاريع التجارية بشكل قانوني؟ ▼
ما الحد الأدنى لمواصفات الجهاز لتشغيل نموذج لغوي مفتوح المصدر؟ ▼
هل النماذج مفتوحة المصدر آمنة للاستخدام مع بيانات حساسة؟ ▼
ما الفرق بين النموذج الأساسي (Base) ونموذج المحادثة (Chat/Instruct)؟ ▼
كم يستغرق تدريب نموذج مفتوح المصدر من الصفر؟ ▼
هل تدعم النماذج مفتوحة المصدر اللغة العربية بشكل جيد؟ ▼
ما هو التكميم (Quantization) ولماذا هو مهم؟ ▼
هل يمكن تشغيل النماذج مفتوحة المصدر بدون اتصال بالإنترنت؟ ▼
ما هي تقنية RAG وكيف تحسن أداء النماذج المفتوحة؟ ▼
هل ستحل النماذج مفتوحة المصدر محل ChatGPT مستقبلاً؟ ▼
الخلاصة ورؤية مستقبلية
لقد قطعت النماذج مفتوحة المصدر شوطاً هائلاً في سنوات قليلة. من مشاريع أكاديمية متواضعة إلى نماذج تنافس أقوى ما أنتجته الشركات العملاقة. هذا التحول لم يكن ليحدث لولا ثلاثة عوامل: المجتمع التقني المتعاون، التقدم في تقنيات الضغط والتحسين، والقرارات الإستراتيجية لشركات مثل Meta وMistral بفتح نماذجها.
بالنسبة للمنطقة العربية والسعودية تحديداً، الفرصة أمامنا هائلة. بنية تحتية رقمية متقدمة، استثمارات ضخمة في الذكاء الاصطناعي ضمن رؤية 2030، وجيل شاب متعطش للتكنولوجيا. ما ينقصنا هو بناء مجتمع عربي نشط حول هذه النماذج: مطورون يبنون نماذج متخصصة بالعربية، وشركات تتبنى حلولاً مفتوحة بدلاً من الاعتماد الكامل على الحلول الأجنبية المغلقة، ومؤسسات أكاديمية تدمج هذه التقنيات في مناهجها.
رؤيتنا في موقع “خلية” هي أن نماذج الذكاء الاصطناعي مفتوحة المصدر ستصبح خلال السنوات الثلاث القادمة البنية التحتية الافتراضية لمعظم تطبيقات الذكاء الاصطناعي في المنطقة. ليس لأنها الأرخص فحسب، بل لأنها تمنح المؤسسات ما لا يمكن لأي حل مغلق أن يمنحه: السيادة على بياناتها وقراراتها التقنية.
إذاً، السؤال الذي يجب أن تطرحه على نفسك الآن ليس “هل أستخدم النماذج مفتوحة المصدر؟” بل “كيف أبدأ اليوم في بناء قدراتي حولها؟”
اقرأ أيضاً: التعلم الآلي والإحصاء: كيف يتكاملان لفهم البيانات وصنع القرار؟
📋 المعايير والبروتوكولات العلمية المعتمدة في هذا المقال
- تصنيف النماذج ومقارنتها استند إلى معايير القياس المعتمدة في Hugging Face Open LLM Leaderboard التي تستخدم اختبارات MMLU وHellaSwag وARC وTruthfulQA.
- تعريف “الذكاء الاصطناعي مفتوح المصدر” يتبع المعيار الرسمي OSAID v1.0 الصادر عن Open Source Initiative في أكتوبر 2024.
- إحصائيات اتجاهات الصناعة مستقاة من تقرير Stanford HAI AI Index 2024 الصادر عن معهد الذكاء الاصطناعي المتمحور حول الإنسان بجامعة ستانفورد.
- معايير حماية البيانات تتوافق مع نظام حماية البيانات الشخصية السعودي (PDPL) الصادر عن الهيئة السعودية للبيانات والذكاء الاصطناعي (SDAIA).
- تقييم مخاطر الأمن السيبراني يستند إلى إطار عمل NIST AI Risk Management Framework الصادر عن المعهد الوطني للمعايير والتكنولوجيا الأمريكي.
⚠️ تحذير وإخلاء مسؤولية
المعلومات الواردة في هذا المقال مُقدَّمة لأغراض تعليمية وتثقيفية فقط، ولا تُشكّل نصيحة تقنية أو قانونية أو استثمارية مباشرة. مجال الذكاء الاصطناعي يتطور بسرعة استثنائية، وقد تتغير المعلومات المتعلقة بالنماذج وتراخيصها وأدائها بشكل مستمر.
يُنصح القارئ بالرجوع دائماً إلى الوثائق الرسمية للنماذج والتحقق من شروط الترخيص قبل أي استخدام تجاري. كما يجب استشارة متخصصين في الأمن السيبراني وحماية البيانات عند التعامل مع بيانات حساسة.
موقع خلية لا يتحمل أي مسؤولية عن قرارات تقنية أو مالية تُتخذ بناءً على محتوى هذا المقال. جميع أسماء المنتجات والعلامات التجارية المذكورة هي ملك لأصحابها.
🔍 بيان المصداقية والشفافية
التزم فريق التحرير في موقع خلية بالمعايير التالية أثناء إعداد هذا المقال:
- جميع المعلومات التقنية مستندة إلى أوراق بحثية محكمة وتقارير مؤسسية رسمية منشورة بين 2023 و2025.
- الإحصائيات والأرقام المذكورة موثقة بمصادرها الأصلية المذكورة في قسم المراجع.
- لم يتلقَّ الموقع أي تمويل أو رعاية من أي شركة مذكورة في المقال (Meta، Mistral، Google، أو غيرها).
- المقال لا يُروّج لنموذج بعينه، بل يقدم مقارنة موضوعية تخدم القارئ والباحث.
المصادر التي جرت مراجعتها تشمل: أوراق بحثية من arXiv وNature، تقارير من Stanford HAI وIBM Security، ووثائق رسمية من Open Source Initiative وSDAIA.
تمت المراجعة العلمية
هيئة التحرير العلمية
موقع خلية
2026
المصادر والمراجع
- Touvron, H., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint. https://doi.org/10.48550/arXiv.2307.09288
- الورقة الأصلية لنموذج Llama 2 التي شرحت بنية النموذج ومنهجية تدريبه.
- Jiang, A.Q., et al. (2023). Mistral 7B. arXiv preprint. https://doi.org/10.48550/arXiv.2310.06825
- الورقة التقنية لنموذج Mistral 7B التي وضحت تفوقه على نماذج أكبر حجماً.
- Sengupta, N., et al. (2023). Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models. arXiv preprint. https://doi.org/10.48550/arXiv.2308.16149
- الورقة التأسيسية لنموذج Jais العربي من معهد الابتكار التكنولوجي.
- Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized Language Models. Proceedings of NeurIPS 2023. https://doi.org/10.48550/arXiv.2305.14314
- دراسة رائدة في تقنيات الضبط الدقيق الفعّال للنماذج المفتوحة.
- Singhal, K., et al. (2023). Large language models encode clinical knowledge. Nature, 620, 172–180. https://doi.org/10.1038/s41586-023-06291-2
- دراسة من مجلة Nature تثبت قدرة النماذج اللغوية الكبيرة على ترميز المعرفة السريرية.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. https://doi.org/10.48550/arXiv.2412.19437
- التقرير التقني لنموذج DeepSeek-V3 الذي أحدث ضجة بتكلفة تدريبه المنخفضة.
- Stanford University, HAI. (2024). AI Index Report 2024. https://aiindex.stanford.edu/report/
- تقرير جامعة ستانفورد السنوي الذي يرصد اتجاهات الذكاء الاصطناعي عالمياً.
- Open Source Initiative. (2024). The Open Source AI Definition v1.0. https://opensource.org/ai/open-source-ai-definition
- التعريف الرسمي للذكاء الاصطناعي مفتوح المصدر من منظمة OSI.
- European Parliament. (2024). Regulation (EU) 2024/1689 – Artificial Intelligence Act. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
- النص الرسمي لقانون الذكاء الاصطناعي الأوروبي الذي يتضمن أحكاماً خاصة بالنماذج المفتوحة.
- IBM Security. (2024). Cost of a Data Breach Report 2024. https://www.ibm.com/reports/data-breach
- تقرير IBM السنوي عن تكلفة اختراقات البيانات عالمياً.
- SDAIA – Saudi Data and AI Authority. (2023). National Data Management Office – Personal Data Protection Law. https://sdaia.gov.sa/
- الإطار التنظيمي السعودي لحماية البيانات الشخصية.
- Penedo, G., et al. (2023). The RefinedWeb Dataset for Falcon LLM. Proceedings of NeurIPS 2023 Datasets and Benchmarks Track. https://doi.org/10.48550/arXiv.2306.01116
- الورقة التي تصف مجموعة بيانات RefinedWeb المستخدمة في تدريب نموذج Falcon.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016).Deep Learning. MIT Press. https://www.deeplearningbook.org/
- الكتاب المرجعي الأشهر في التعلم العميق.
- Jurafsky, D., & Martin, J.H. (2024).Speech and Language Processing (3rd ed. draft). https://web.stanford.edu/~jurafsky/slp3/
- المرجع الأكاديمي الأساسي في معالجة اللغات الطبيعية.
- Russell, S., & Norvig, P. (2021).Artificial Intelligence: A Modern Approach (4th ed.). Pearson. http://aima.cs.berkeley.edu/
- أشهر كتاب جامعي في الذكاء الاصطناعي عالمياً.
قراءات إضافية ومصادر للتوسع
- Bommasani, R., et al. (2021). On the Opportunities and Risks of Foundation Models. arXiv preprint. https://doi.org/10.48550/arXiv.2108.07258
- لماذا نقترح عليك قراءته؟ هذه الورقة من جامعة ستانفورد (أكثر من 200 صفحة) تُعَدُّ “دستور النماذج الأساسية”. تشرح المفهوم من كل الزوايا: التقنية، الأخلاقية، الاقتصادية، والاجتماعية. إذا كنت تريد فهماً شاملاً لكل ما يتعلق بالنماذج الكبيرة — مفتوحة ومغلقة — فهذا هو نقطة البداية المثالية.
- Vaswani, A., et al. (2017). Attention Is All You Need. Proceedings of NeurIPS 2017. https://doi.org/10.48550/arXiv.1706.03762
- لماذا نقترح عليك قراءته؟ هذه الورقة هي حجر الأساس الذي بُنيت عليه كل نماذج المحولات (Transformers) الحديثة، من BERT إلى GPT إلى Llama. فهمها يعني فهم “المحرك” الذي يُشغّل كل نموذج لغوي كبير تتعامل معه اليوم.
- Wolf, T., et al. (2020). Transformers: State-of-the-Art Natural Language Processing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). https://doi.org/10.18653/v1/2020.emnlp-demos.6
- لماذا نقترح عليك قراءته؟ هذه الورقة تشرح مكتبة Hugging Face Transformers التي أصبحت المنصة القياسية لتشغيل النماذج مفتوحة المصدر. فهم هذه المكتبة ضروري لأي مطور يريد العمل عملياً مع هذه النماذج.
إذا وصلت إلى هنا، فأنت الآن تملك خريطة شاملة لعالم النماذج مفتوحة المصدر. الخطوة التالية؟ حمّل نموذجاً مفتوحاً اليوم — Ollama يجعل الأمر بسيطاً — وابدأ بتجربته على مهمة واحدة صغيرة تتعلق بعملك. لا تنتظر أن تفهم كل شيء قبل أن تبدأ. ابدأ أولاً، وسيأتي الفهم مع الممارسة. شاركنا تجربتك في التعليقات، أو تواصل معنا عبر موقع خلية إذا احتجت إلى توجيه مخصص.




